Conhecimento num único lugar.
Engenharia de Aplicações - Adriano Guedes
Este artigo analisa um cenário típico com Multi Chassi Link Agregation (MC-LAG) e exercita como a arquitetura planejada pode extrair o máximo de resiliência de um cenário de implantação com MC-LAG em uma rede L2 existente, inclusive mitigando cenários onde ocorre o split-brain.
O fenômeno conhecido como split-brain, ocorre quando dois ou mais nós de um sistema que deveriam operar em conjunto, perdem a comunicação entre si, porém continuam ativos de forma independente, cada um, acreditando que o outro nó está inativo. É como se os dois dispositivos que deveriam operar em modo ativo/passivo, atuassem como ativo, impactando diretamente na escalabilidade da topologia, gerando instabilidade e perdas de conectividade.
Tradicionalmente uma agregação de links, onde várias interfaces físicas se comportam como uma interface lógica, operam sempre de um equipamento A para um equipamento B, realizando a distribuição do tráfego de acordo com a sua variabilidade, entre as interfaces disponíveis, como visualizado na imagem abaixo.

O balanceamento pode ocorrer por critérios como:
Não há um método melhor ou pior, mas sim, aquele que se adapta as características da sua topologia.
Já o MC-LAG, traz a ideia da agregação de links físicos em um lógico, mas com a possibilidade de que seja estabelecido com destinos distintos, conforme abaixo.
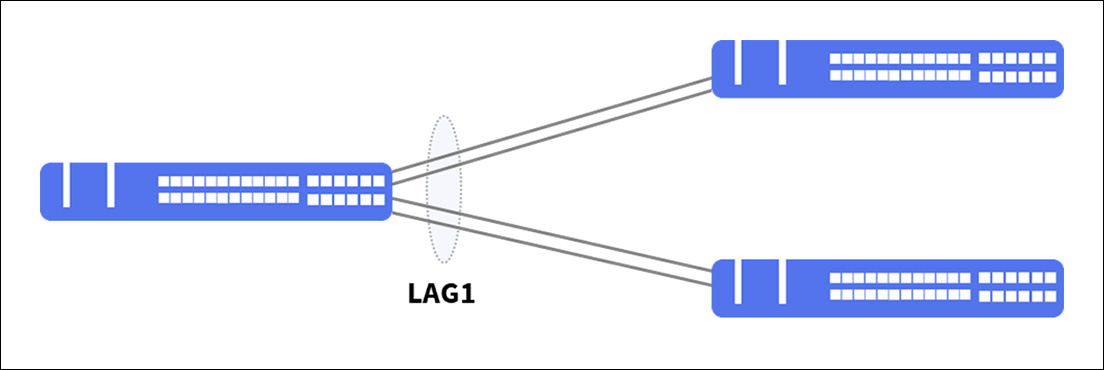
Tornando-se uma excelente solução para fornecer redundância, resiliência e balanceamento de carga em ambientes críticos.
Nos equipamentos com sistema operacional DmOS, o MC-LAG funciona no modo Active/Standby, onde um dos PEs assumirá o papel de ativo, e o outro, o papel standby, servindo como um dispositivo backup. O tráfego será encaminhado apenas para o dispositivo PE sinalizado como ativo.
A configuração entre os PEs envolve os parâmetros de:
Já para o funcionamento do MC-LAG, teremos:

A configuração do lag-priority de menor índice definirá qual será a conexão física (das duas alocadas para o link aggregation) do LAG que será percorrida pelo tráfego, denominada ativa, e qual ficará em espera, denominada standby. Deve ser evitado o uso do mesmo valor de lag-priority nos dois PEs.
Os pares do MC-LAG utilizam o Inter-Chassis Control Protocol (ICCP) para trocar informações de controle e coordenar entre si, garantindo que o tráfego de dados seja encaminhado corretamente.
O LACP é usado para descobrir vários links de um dispositivo CE conectado a um par MC-LAG e deve ser configurado em ambos os pares MC-LAG para o funcionamento correto.
O parâmetro de admin-key do LAG entre os PEs deverá ser igual, o DmOS utiliza mesmo valor do ID do LAG como admin-key.
A seguir temos um cenário típico de MC-LAG, com as condições perfeitas de funcionamento entre todos os equipamentos, reforçamos que a topologia é composta pelo CE A – identificado pela imagem de um computador e os switches PE A e PE B.
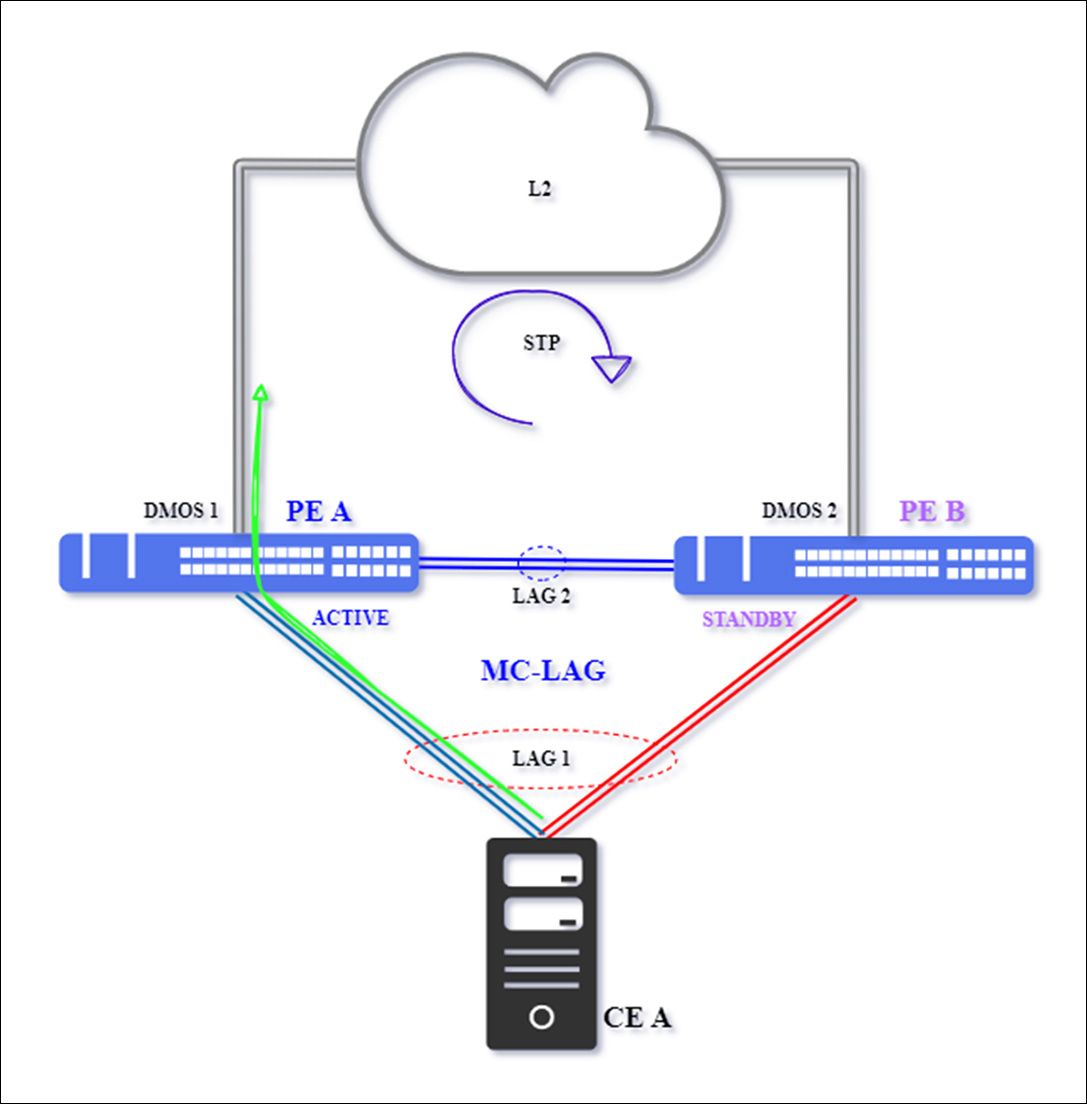
Cenário Tradicional de MC-LAG
O fluxo de dados será encaminhado pela interligação ativa do LAG 1, sinalizado pela seta verde, entre o PE A e o CE A, seguindo pela interface de uplink principal com a rede L2 acima dos dois switches configurados em MC-LAG, o equipamento PE B será mantido com o status standby e sem tráfego de dados, entre PE B e o CE A.
A rede L2, identificada pela nuvem na imagem acima, possuirá protocolos para a prevenção de loops lógicos, como spanning-tree (xSTP), EAPS, ERPS ou outros, logo, a porta por onde o tráfego será encaminhado, no nosso caso a do PE A – DmOS 1 deverá estar ativa/liberada.
Em situações normais de operação de uma rede, os enlaces estão sujeitos a falhas simples e mais complexas, que detalhamos a seguir, os quais, geram 5 comportamentos distintos.
Caso 1 – Falha Única entre CE e PE
A falha, sinalizada com um “X” vermelho na topologia abaixo, ocorre em uma das conexões físicas que compõem o LAG1, e opera como link principal de interligação entre PE A e CE A.
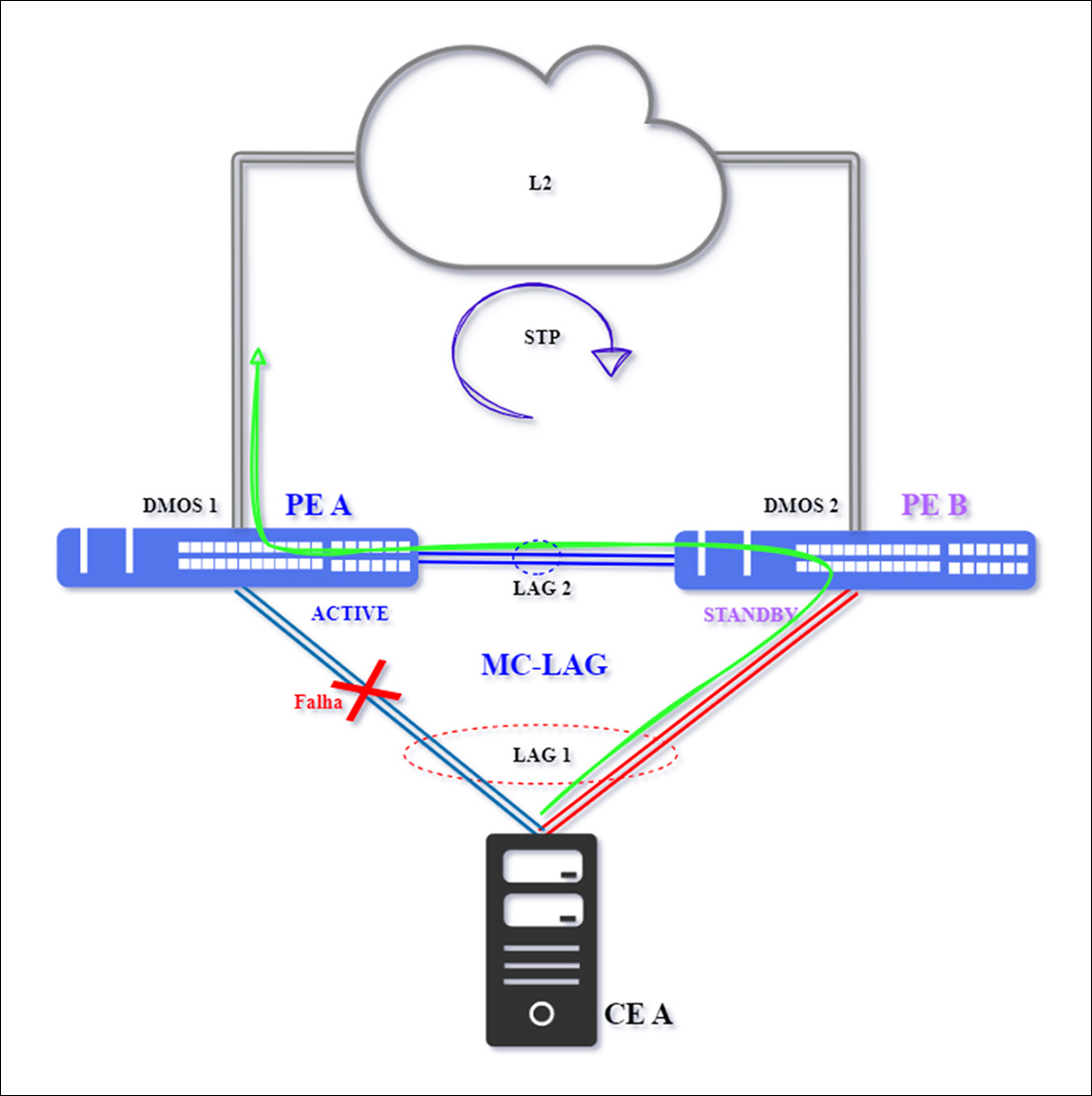
Observe que o equipamento PE A – DmOS 1 permanece como ativo, pois não houve perda na comunicação com o PE B – DmOS 2, logo o tráfego fluirá pelo outro membro do LAG1, a conexão entre o CE A e PE B. Já o encaminhamento do tráfego para a rede L2 continuará pelo PE A, pois percorre a interligação entre os dois switches (A e B) em MC-LAG.
A normalização ocorrerá após a interligação principal entre PE A e CE A ficar disponível.
Caso 2 – Falha Única entre PEs
A falha ocorre no link de interligação entre os PEs, é onde ocorre a situação de Split Brain.
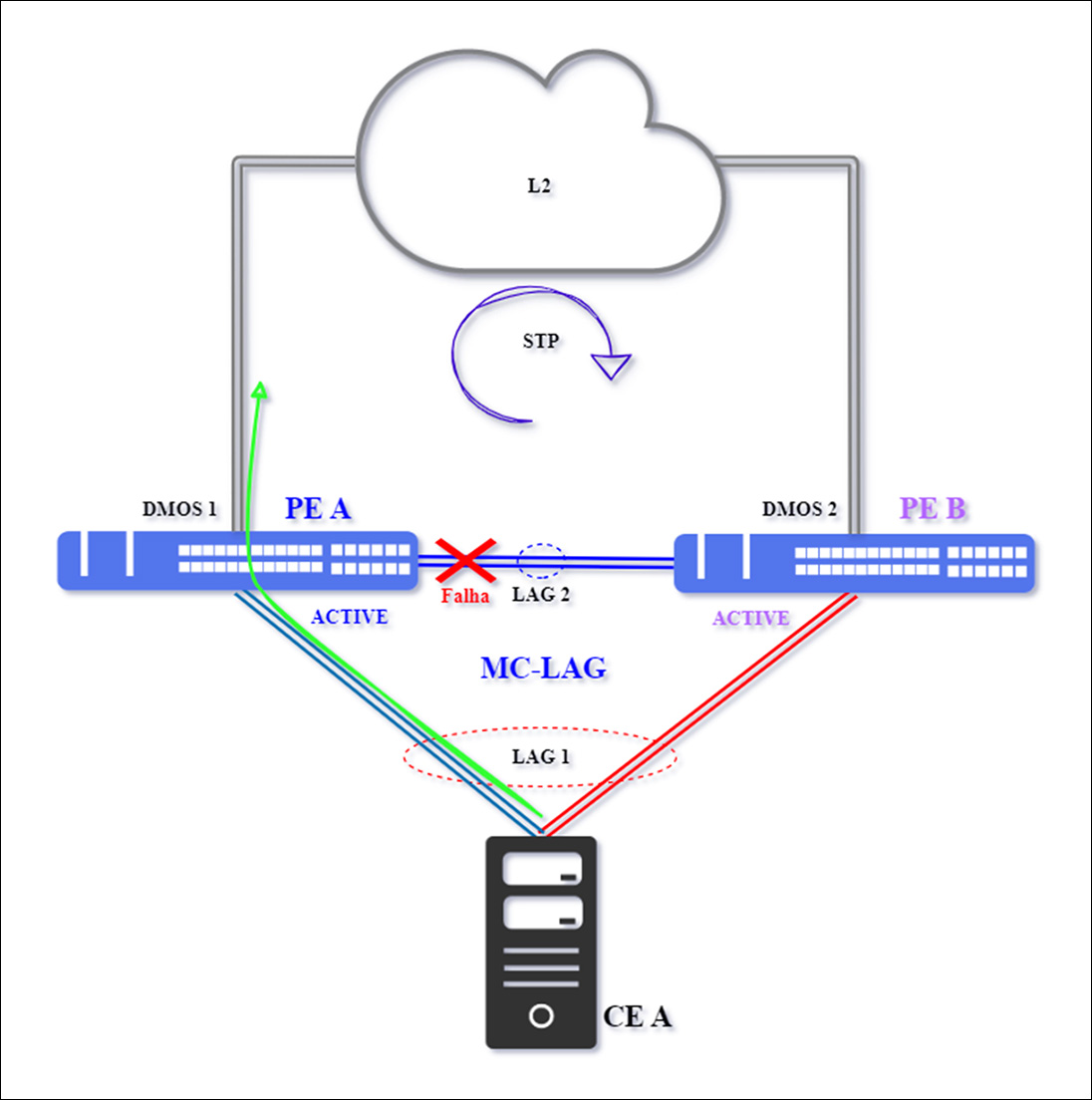
No cenário acima, em teoria, haverá a condição de split brain. A comunicação entre os PEs é interrompida, fazendo com que o PE A permaneça em estado Ativo, porém, o PE B terá o seu status alterado para Ativo.
Na prática, o tráfego do MC-LAG continuará fluindo sem perturbações, não haverá a convergência do tráfego para o PE B, contudo é importante que a conexão entre os PEs seja reestabelecida, pois é um ponto de atenção na arquitetura MC-LAG.
O valor de System Priority define a preferência do equipamento na seleção dos links ativos em um LAG. Esse valor é transmitido nos LACPDUs, permitindo que o equipamento remoto (CE), interprete corretamente a hierarquia de prioridade entre os sistemas.
Para restaurar o funcionamento, é necessário garantir a normalização do link de controle entre os PEs, permitindo que o PE B retorne ao estado de Standby, mantendo o PE A como único Ativo.
Caso 3 – Falha Única no PE Ativo
A falha ocorre no equipamento PE A, o qual opera como equipamento ativo do MC-LAG, interrompendo o link principal de interligação entre PE A e CE A, bem como o de interligação entre os PEs.
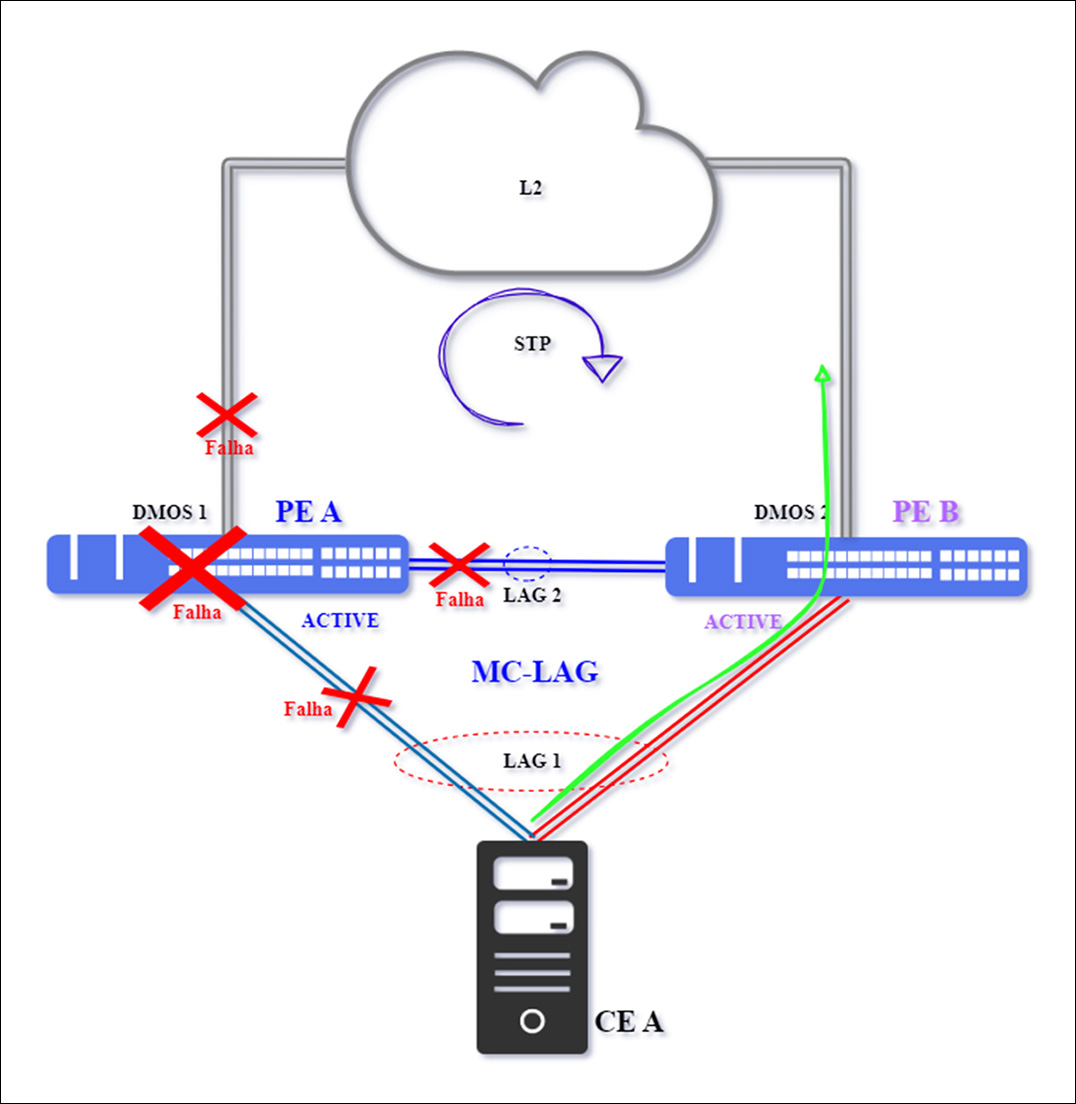
Note que esse cenário representa tanto a falha total do PE A, quanto a interrupção simultânea das 03 conexões (isolamento total) que o conectam à topologia.
O equipamento PE A estará totalmente inoperante, por consequência, o PE B e o CE A perdem a comunicação com o equipamento ativo, fazendo com que o PE B assuma o papel de ativo, aqui, não acontece o split brain, pois apenas o PE B assumirá como ativo.
O tráfego será redirecionado para a conexão secundária do LAG 1 entre PE B e CE A – seta verde. Quanto a interconexão com a rede L2, uma vez que o PE A está totalmente inoperante, a interface será identificada como down, fazendo com que o protocolo de resiliência realize a convergência.
A topologia será reestabelecida após o equipamento PE A e suas conexões serem normalizadas.
Caso 4 – Falha Dupla no PE Ativo
O isolamento do PE A (equipamento ativo do MC-LAG) pode ocorrer por dupla falha, quando o link interligação entre PE A e CE A e de interligação entre os PEs estão inativos, como por exemplo, um rompimento.
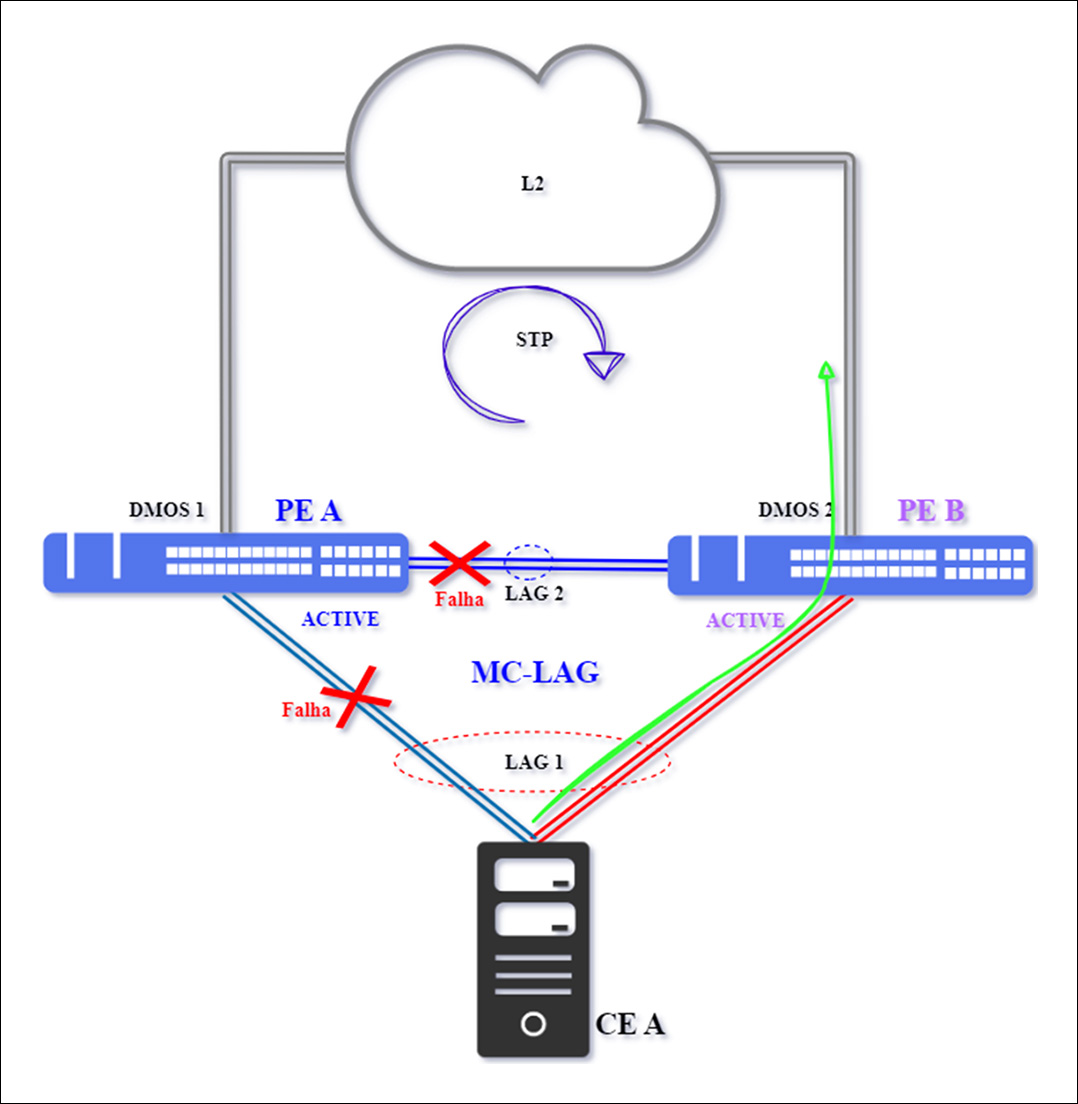
Com esta falha, o equipamento PE A e PE B perdem a comunicação e ambos passam a ficar com status Ativo, ocorrendo o fenômeno conhecido como split brain, porém, mesmo com os dois PEs assumindo o status de Ativo, não haverá impacto, pois existe uma falha na conectividade principal do LAG 1 entre PE A e CE A, sinalizado pelo “X” em vermelho. O tráfego será redirecionado para a interligação secundária entre CE A e PE B.
Destaca-se que a interconexão com a rede L2 (nuvem) está fora do contexto do MC-LAG, a continuidade da comunicação, dependerá do protocolo de resiliência utilizado na rede e que seja capaz de perceber que o PE A não é mais um caminho válido e ativo para o CE A, realizando a convergência do tráfego para a conexão com o PE B.
Para reestabelecer a topologia, ative em primeiro lugar a interligação entre PE A e PE B, de forma que somente o equipamento PE A fique com status Ativo, para na sequência garantir que a interligação entre o PE A e CE A seja normalizada.
Caso 5 – Falha Dupla no CE
Ocorre com o isolamento do CE por dupla falha nos links principal e secundário do LAG 1, aqueles utilizados para a interligação com os PEs.
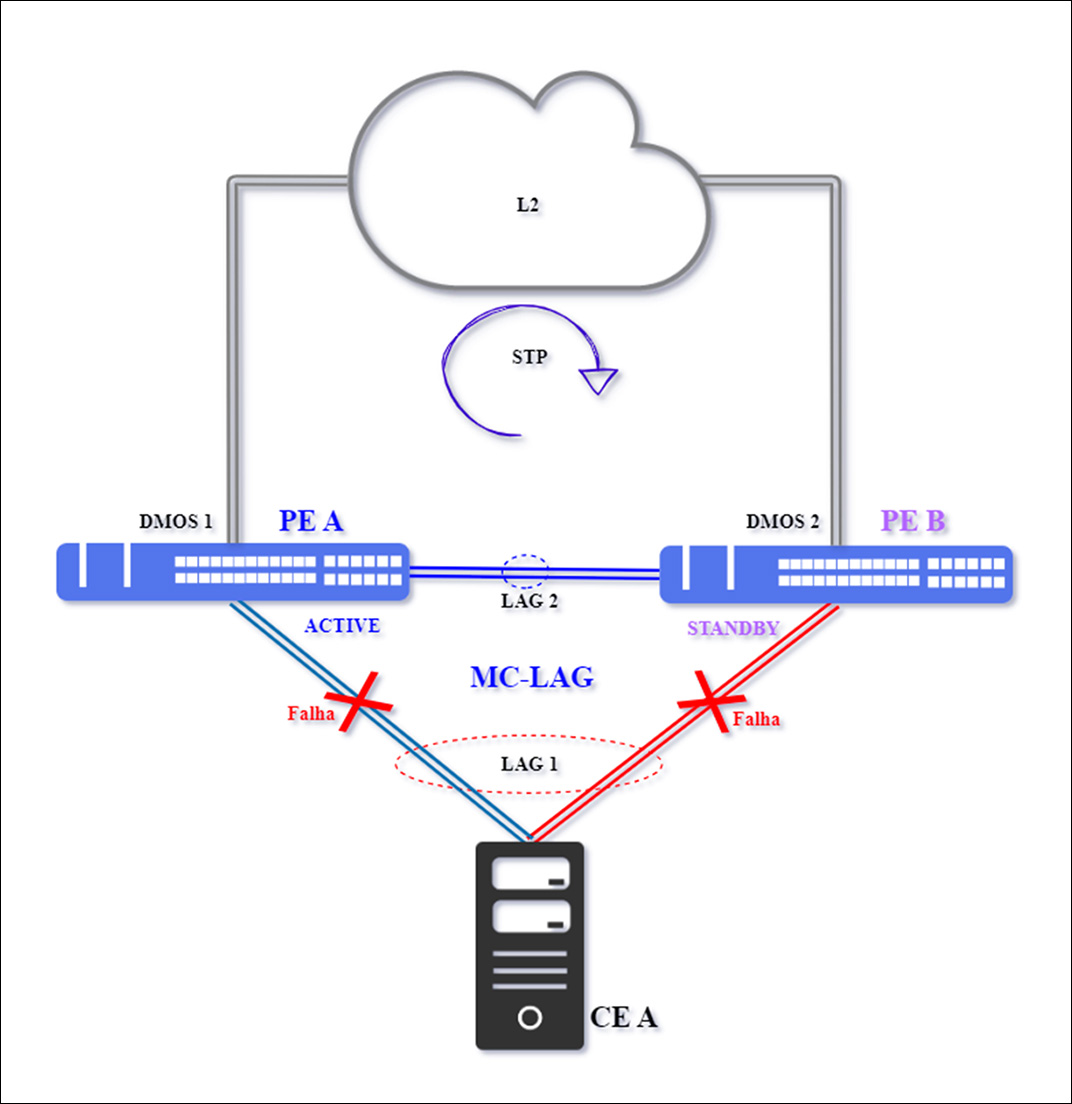
Esta falha não é comum, mas provoca interrupção total do tráfego.
O PE A permanecerá com o status Ativo e PE B como Standby, devido a comunicação entre PEs continuar operacional. Trata-se aqui da concretização do risco de ter um único CE.
O tráfego será reestabelecido após a normalização do CE A.
Conclusão
O DmOS adota uma abordagem simplificada em relação ao vPC da Cisco, eliminando a necessidade de canais paralelos de controle (Peer-Link e Keepalive), o que reduz a complexidade e o custo de infraestrutura e configuração, sem comprometer a resiliência. A solução Cisco vPC é ilustrada nesta documentação externa: 🔗 vPC Failure Scenarios – Impact and Solution
Recomendamos a leitura do tópico MC-LAG do nosso guia de configuração rápida do DmOS, onde destacamos a aplicação de prioridades diferentes nos campos system priority e mc-lag lag-priority.
Essa prática é essencial para evitar impactos no tráfego em caso de perda da sessão de controle do MC-LAG (ICCP), como apresentado no Caso 2.
O recurso MC-LAG destaca-se pela entrega de serviços e pela alta disponibilidade entre switches, evitando a interrupção total do tráfego do cliente e está presente em cenários de datacenter, provedores de Internet e ambientes corporativos.
As possíveis falhas mencionadas visam alertar a possibilidade de ocorrência do split-brain, o qual poderá comprometer a integridade da rede, porém com dicas e com planejamento a mitigação dos problemas torna-se mais eficaz.
O parâmetro System Priority é incluído nas LACPDUs (Link Aggregation Control Protocol Data Units) trocadas durante o estabelecimento do LACP entre os equipamentos PEs e o equipamento CE.
A identificação única de um sistema (System ID) é composta pela concatenação de um endereço MAC único administrado e pelo System Priority configurado, ou seja, a prioridade do sistema influencia diretamente qual lado será eleito como o sistema principal no LAG.
Em resumo, o equipamento com o menor valor de System Priority será selecionado como ativo e terá os links principais no LAG, pois esse parâmetro é enviado nos pacotes de controle LACPDU, garantindo que o equipamento remoto (CE) identifique e aplique corretamente as prioridades recebidas, desde que implemente a norma IEEE 802.1AX.
A solução MC-LAG entre PEs foi desenvolvida para operação entre equipamentos do mesmo fabricante, não garantindo interoperabilidade com terceiros. Já o equipamento posicionado como CE, sim, desde que atenda ao IEEE 802.1AX, pois o LACP foi projetado para interoperar entre fabricantes diferentes.
Os casos apresentados ilustram falhas hipotéticas que são amplamente mitigáveis com as boas práticas de configuração abordadas neste artigo.
Todas as configurações estão disponíveis no nosso “DmOS – Guia de Configuração Rápida” e em https://www.datacom.com.br/pt/blog/120/mc-lag-no-dmos-alta-disponibilidade-e-escalabilidade-em-infraestruturas-de-rede.
Se surgir qualquer dúvida ao longo do processo, nosso time Suporte - Datacom e Comercial - Datacom está pronto para apoiar você em cada etapa, garantindo excelência, agilidade e evolução contínua para o seu negócio.
Lembrando que a Datacom conta com uma estrutura completa em sua matriz onde são ofertados treinamentos presenciais, bem como uma plataforma de treinamentos on-line (DATACOM EAD). Nos treinamentos será possível realizar configurações de diversas topologias e cenários de aplicação, além de poder contar com a ajuda dos nossos profissionais em uma série de boas práticas que ajudarão muito na operação de sua rede.
Inscreva-se também no nosso canal do YouTube, marque o recebimento de notificações e compartilhe o link nas suas redes sociais.
Voltar para o blog
